
El pasado 12 de mayo, inmediatamente después del tweet de Elon Musk respecto a que Tesla dejaría de aceptar bitcoins como medio de pago para sus vehículos, vimos un aumento del 1.100% en las visitas a nuestras plataformas. Esto produjo una caída de algunos de nuestros servicios y una intermitencia que duró dos horas, resultando en que muchos de nuestros usuarios no pudieran acceder a sus cuentas, ya sea desde la plataforma web o la aplicación móvil.
La sección de vista trader en nuestra web y la vista principal de nuestra aplicación se vieron especialmente afectadas, ya que ambas muestran gráficos de precio, información muy solicitada por nuestros usuarios en ese momento.
¿Qué pasó?
A continuación, les contamos uno de los principales problemas que encontramos en esta caída.
Para generar los gráficos, consultamos a nuestro clúster de ElasticSearch, donde guardamos un time series con los volúmenes y precios de los diferentes mercados. El aumento en la demanda resultó en un incremento de 3.300% en la cantidad de datos que este tuvo que procesar y contestar.
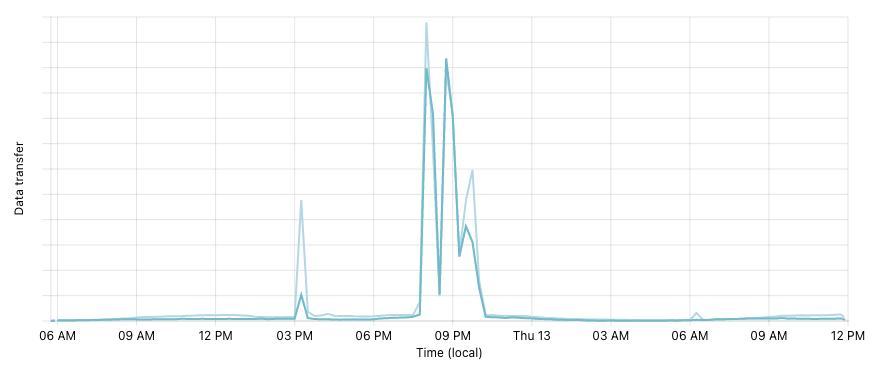
Lo anterior hizo que los requests a nuestro cluster comenzaran a ser muy lentos.
Por otro lado, nuestro ingress proxy llego al límite de las conexiones, lo que produjo que no pudiera contestar nuevos request. Esto se vio incrementado por el problema con elasticsearch, dado que al aumentar el tiempo de respuesta considerablemente, la cantidad de conexiones simultáneas también aumentó a una tasa que no teníamos presupuestada.
¿Qué hicimos para mejorar?
Es muy importante buscar la forma de prevenir que esta situación vuelva a ocurrir. Para esto, implementamos varias mejoras en nuestra plataforma. Aquí les contamos las más importantes:
- Agregamos una capa de cache delante de ElasticSearch (ES), esto previene que múltiples requests con las mismas características tengan que ser procesadas por ES, liberando recursos de nuestro clúster y haciendo que, en general, las respuestas sean mucho más rápidas.
- Aumentamos la capacidad de conexiones simultáneas que nuestro proxy puede soportar y estamos planificando para poder escalar de manera automática en función del tráfico
Timeline del incidente
- 20:07 Primer peak de tráfico
- 20:20 Como primera medida, reiniciamos nuestros proxies de entrada.
- 20:23 Comunicamos el incidente en status.buda.com
- 20:50 Nos percatamos que la base de datos estaba usando el 100% de la CPU.
- 21:01 Escalamos la base de datos.
- 21:05 Terminó el resize de la base de datos.
- 21:14 Se reporta caída y lentitud nuevamente. Descartamos que la BBDD sea el problema.
- 21:48 Identificamos un problema con la memoria de ElasticSearch.
- 22:03 Aumentamos las réplicas y la memoria de ElasticSearch.
- 22:06 Vemos que comienzan a bajar los tiempos de respuesta.
- 22:13 Comunicamos en status.buda.com que el sitio está estable.
¿Por qué nos tomó tanto tiempo solucionar el problema?
Nos demoramos más de lo que habríamos esperado en detectar y solucionar el problema por dos principales razones, de las cuales podemos sacar aprendizajes para estar mejor preparados.
La primera es porque nos faltó tener mejor visibilidad en el estado de nuestro ingress proxy, y disponibilidad en general. Lo que sumado a la inestabilidad general de la plataforma nos hizo buscar los problemas por el lugar equivocado.
La segunda razón, es porque nuestro sistema de autoscaler genera un problema cuando la página esta caída, dado que reacciona muy rápido haciendo scale-down, dejándonos sin recursos para procesar requests una vez que la página está arriba. Esto genera un círculo vicioso que sólo empeora la visibilidad de donde está realmente el problema.
Conclusión
Esta caída fue muy dura, ya que ocurrió en un momento peak, cuando gran parte de nuestros usuarios más querían tener acceso a la plataforma. Pero al mismo tiempo, nos permitió visibilizar algunas fallas que teníamos que mejorar y nos dio pie para empezar a documentar y ser más transparentes en cuanto a lo que pasó y sobre lo que estamos haciendo.
Aprendimos mucho en el camino y de todas formas estamos mejor preparados para cuando volvamos a ver un aumento repentino en la demanda de nuestros servicios.



